
Article Summary
Machine learning is a subfield of AI that trains algorithms on real-world data to build predictive models. This article covers supervised, unsupervised, semi-supervised learning, neural networks, reinforcement learning, and how ML relates to AI. You'll gain a clear, practical understanding of how machine learning works.
What is machine learning? Put simply, machine learning describes computer algorithms trained with real-world data to build predictive models.
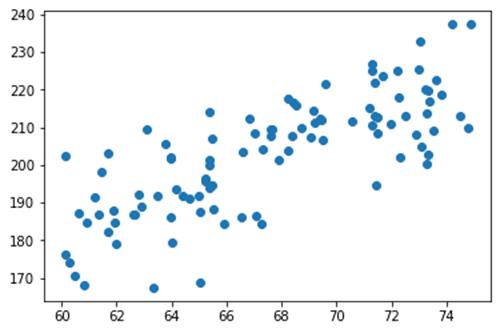
Even though it’s a subfield of artificial intelligence (AI), machine learning isn’t as complicated as it may seem. As a simple example, imagine we’ve collected data on the height and weight of 100 people. We call this our training data. We could graph the data we collected with the measured heights on the X-axis and weights on the Y-axis, as seen below.
Recommended Udemy course

Every point on this graph represents the height and weight of a given person. A simple machine learning algorithm could fit a line to this data. We could then use that line to make predictions about the weight of new people given their height. Think of it as a high school math problem. One equation of a line is y = mx + b, where m is the slope of the line and b is the y-intercept. A machine learning algorithm called linear regression can be used to learn the best values of m and b to fit the data we have. In this case, we end up with y = 2.75x + 16.5, which results in this line:
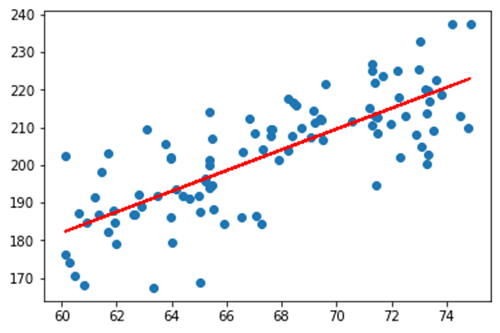
Now that we’ve learned the line that best fits our training data, we can plug in new height values for x and produce predictions of weights on y. See how simple machine learning can be?
Types of Machine Learning
There are different types of machine learning best suited for different kinds of problems. They generally fall into two categories: supervised and unsupervised – but sometimes we combine the two as well.
Supervised Machine Learning
The linear regression we saw above is an example of supervised learning. That means that our training data contains known, correct answers for the thing we’re trying to predict. For each person the linear regression model was trained on, we knew their weight given their height. It’s called supervised because we can easily evaluate how good our model is while it is being trained by comparing it to known correct answers. Most machine learning algorithms fall into the supervised learning category including regression, decision trees, XGBoost, and many more.
In the world of machine learning, the thing we’re trying to predict is the label. So, we say that supervised machine learning deals with labeled training data.
Unsupervised Machine Learning
Sometimes, we’re trying to uncover unseen patterns in the data we have. For example, what are the broader topics that describe a set of documents? Can we categorize movies based on how similar their plot summaries and scripts are? We might not know what the set of topics or movie genres are ahead of time, but unsupervised learning techniques can uncover them. These unknown attributes are called latent features. Techniques such as K-means clustering, principal component analysis, latent Dirichlet allocation, and K-nearest-neighbors can be used to uncover these latent features.
As we don’t know the correct answers ahead of time, unsupervised algorithms use unlabeled training data.
Semi-Supervised Learning
Real-world projects aren’t always so cut and dry. Imagine you have a large set of training data, but only some of it comes with labels (known correct answers.) This is a common situation; many problems require a human to label data before it can be used to train a machine learning algorithm. For example, training an image recognition system might require humans to manually classify objects in a set of images used to train the system. However, you may have many more images that need labeling than you’re actually able to label because you only have so many humans.
This where semi-supervised learning comes in. You can use supervised learning to train a model that assigns labels to unlabeled data, based on the human-generated labels it receives. Over time, we can compare the labels produced by the supervised algorithm to the labels produced by humans. As they start to agree, we can use the supervised model to label our training data instead of humans in cases where the model has high confidence. Those machine-generated labels are called pseudo-labels.
As our training data now contains a mixture of known labels assigned by humans and data that was inferred by a model, these models are called semi-supervised.
What about neural networks?
Neural networks don’t fit neatly into the aforementioned machine learning categories. Rather, they are highly flexible algorithms that can be used for supervised, unsupervised, and semi-supervised learning. If you’re looking for a one-size-fits-all machine learning algorithm that can solve almost any problem, neural networks are it.
A neural network is inspired by the biology of the human brain, although modern neural networks have diverged considerably from their biological counterparts. Today, neurons are still a useful metaphor for understanding how neural networks work, but under the hood, they are basically driven by linear algebra and calculus that has been optimized for the best results.
Conceptually, you can think of a neural network as layers of virtual “neurons” that are all interconnected. Here’s an example of a neural network architecture:
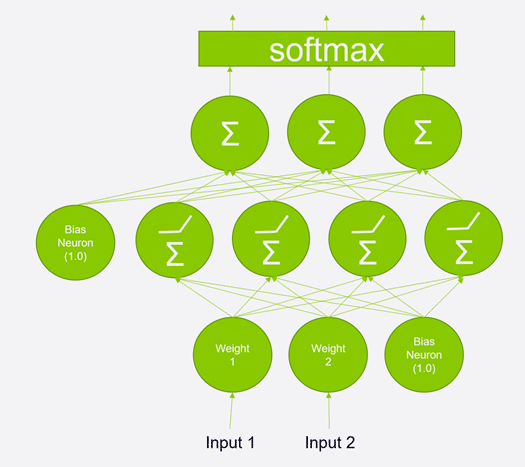
This hypothetical network will be used to classify things based on their features. Maybe I’m trying to predict which genre a movie is based on the directors and actors involved in it. We feed those features – the actors and directors – into the bottom on this neural network. Once the network is trained, it will produce probabilities of the movie being in one of many different genres in the output at the top.
Each circle in this diagram represents a neuron, although they are largely referred to as “units” these days. In between the top and bottom of this network are several layers of neurons, all of them interconnected. Each neuron’s job is to sum up all the signals coming into it (which is what the Sigma symbol means) and apply an activation function to decide what signal is output to the next layer (that’s what the bent line represents).
The magic of neural networks happens when we train them to learn the optimal weights and biases between each neuron. A technique called gradient descent is used to find the best weights to assign to each connection. As there are many different weights that can have many different values, neural networks can represent very complex problems. The massive jumble of weights we end up with makes it hard to understand intuitively why a given trained neural network produces the answers it does, but it generally works quite well.
Neural networks have dominated machine learning research in recent years because they are extremely flexible and can be applied to a wide range of complex problems. However, they’re not always the optimal solution and tuning them for the best performance can be very challenging.
What about artificial intelligence?
Neural networks, AI, and machine learning are often used interchangeably – but they are different things.
AI is a broader category than machine learning. Early attempts at AI did not use machine learning algorithms at all; instead, many were rule-based systems. Early conversational bots were actually made up of pre-programmed responses for a set of keywords they could reference depending on the asked question. If you said the word “happy,” the bot might have a human-generated rule to respond with “I’m glad you’re feeling good about that!” The behavior of an AI system like this is explicitly programmed, and not something that is learned as it goes.
Modern AI tends to rely more on machine learning, of which neural networks are one of several approaches. A neural network could learn that an appropriate response to “I feel happy” is “I’m glad you’re feeling good about that” just based on feedback during its training.
Neural networks aren’t the only machine learning techniques used in the field of artificial intelligence. Another popular algorithm is called reinforcement learning, which learns the best way to decide between different states based on the consequences of decisions made during training. For example, a reinforcement learning system could learn how to play Pac-Man by trying random moves and observing which led to being killed by a ghost and which led to finding power pills and eating ghosts. When you read stories about AI systems that beat humans at video games or board games, that’s likely reinforcement learning techniques in use.
Complex AI systems, like self-driving cars, might combine different techniques. A neural network could be used to identify street signs, while reinforcement learning is used to learn how to best navigate streets, and there are probably plenty of rule-based systems in there too.
So, working our way up, neural networks are a subset of machine learning, and machine learning is a subset of artificial intelligence. They’re not the same thing.
Machine learning’s dirty secrets
The world of machine learning research is steeped in fancy math, algorithms, and terminology – but this hides some unpleasant truths. If you enter the field of machine learning in the real world, you’ll find that playing with algorithms is a rather small part of the job.
Despite its complex algorithms, successful machine learning systems are largely the result of trial and error. We give this a fancy name: hyperparameter tuning. These models generally have many hyperparameters, such as learning rates, how many layers your neural network has, and how many neurons are in each layer – and there’s rarely a good way to know what the best values of these parameters are for a given problem. Machine learning practitioners tune their models by simply trying a wide variety of combinations of these parameters and seeing which ones work best experimentally. At the end of the day, it’s throwing a bunch of metaphorical spaghetti at the wall and seeing what sticks. There’s nothing fancy about that!
Real-world machine learning is often more about data processing than actual machine learning. Your choice of algorithms and parameters is much less important than the quality of the data you train your machine learning systems with. A data scientist often spends more time analyzing and cleaning the data used to train a system than in working with the algorithms themselves. There’s an entire discipline called feature engineering devoted to preparing and pre-processing your training data to produce the best results. This is typically how a machine learning researcher spends most of their time in the real world. Data analysis, statistical analysis, and dealing with missing data are a big part of the job. When you add the challenge of applying feature engineering to massive amounts of data using cloud computing, it quickly becomes the hard part of applied machine learning.
Even your ability to choose the best algorithm for a problem may be unimportant when on the job. “AutoML” systems can try different algorithms on training data and automatically figure out the best one to use through experimentation. It is possible to simply provide your training data to an AutoML system, perform automated hyperparameter tuning on it, and produce a highly optimized machine learning system with very little involvement or expertise from you. Machine learning systems can now create machine learning systems of their own!
For people new to the field, this is good news – machine learning is more accessible than it has ever been. But people who understand what’s going on under the hood with the why and how of machine learning remain highly valuable in today’s job market.
Are you wondering what the difference between machine learning and deep learning is? Read about it in this article.
