
Article Summary
RDBMS concepts cover the foundational ideas behind relational database management systems—structured storage using tables, rows, columns, keys, and SQL constraints. This article explains database design principles, data integrity rules, and how to organize and link tables effectively. You'll gain a clear, beginner-friendly understanding of how to build a well-structured RDBMS.
 An RDBMS (Relational Database Management System) is essentially a database management system that is designed to store data which can later be used for a specific application. The term “RDBMS” stands for the actual database, which typically comes associated with a variety of supporting functions and software including SQL Queries and System Restores. In short, these databases are an excellent way to store information which will later need to be retrieved.
An RDBMS (Relational Database Management System) is essentially a database management system that is designed to store data which can later be used for a specific application. The term “RDBMS” stands for the actual database, which typically comes associated with a variety of supporting functions and software including SQL Queries and System Restores. In short, these databases are an excellent way to store information which will later need to be retrieved.
They usually contain more than a single table, and similar to a spreadsheet, will contain columns and rows that are used to sort information. From here, data can be deleted, updated, or inserted. With that being said, let’s take a look at some steps that you can follow to successfully build a Relational Database Management System and “insert” new information into it.
Understanding SQL Constraints
“Constraints” are basically rules that are used to govern how the columns on a table function. They are used to limit the kind of data that you’ll find within the table. This will ensure reliability and accuracy for the data that is being entered in the database. Let’s take a look at some of the more commonly used SQL constraints that you’ll encounter:
-
NOT NULL: This constraint is used to ensure that all columns within your database don’t contain a “NULL” value.
-
DEFAULT: Used to provide some kind of default value whenever there isn’t one specified in a column.
-
UNIQUE: Designed to ensure that every single value in a column is unique.
-
PRIMARY: These refer to the rows and records in a table that have been uniquely identified.
-
CHECK: Designed to ensure that all values within a specific column meet the conditions for the database as a whole.
Finally, an “INDEX” can be used to retrieve data as well as create it within a database very quickly.
A Quick Look at Database Design
Whenever you’re constructing a relational database management system from scratch, you’ll need to place a large deal of thought into the process. Otherwise, this will lead to a poorly designed and inefficient database. Here are some reasons why understanding database design is important:
-
Less chance of losing data integrity over an extended period of time.
-
You’ll be able to support more queries that are needed.
-
Higher performance.
It’s safe to say that entire courses have be written about database design, but we don’t have time for that. We’ll crunch down everything you need to know in the section below. Basically, a well thought out database system is one that:
-
Is used for a single purpose.
-
Has one primary key.
-
Doesn’t include a multitude of fields.
-
Doesn’t contain fields that are multi-valued.
-
Doesn’t contain duplicate (and unnecessary) fields.
Finally, a good database management system doesn’t carry redundant data.
Gathering Data for a Relational Database System
Gathering the data that you’d like to insert into your database management system is the first step of the process. Remember that you can arrange and store anything from financial information to information streaming from social media websites like Facebook or Twitter. Let’s say that you were going to gather data from Twitter.
To do this, you could type something like “#Databases” in the search bar. At this point, you’d want to gather information including the username of the account, the actual name, the text that was used during the Tweet, and if possible, the point at which it was created. Note, all of this is real data, which should making finding it quite easy, right?
Well, not exactly. You always want to be sure that you aren’t entering repetitive data. When it comes to operating a successful Relational Database Management System, duplicate information can make the task of inserting or editing information much more challenging than it needs to be. Here’s a beginners guide to using an open source RDBMS called Postgre SQL.
Removing Duplicate Information from Columns and Rows
Let’s use the previous example and build upon that. When acquiring the names of the Twitter users for the term “#Databases”, what if you ran into a situation where the usernames were all following one another? This would definitely cause a problem, as it would result in duplicate information entering the database. That’s why step 2 of the process is to go ahead and remove repetitive information from your RDBMS.
To do this, you would want to create a separate column for Twitter usernames as well as a separate column for Twitter followers. That way, even if there is repetitive information, you’d be able to easily sort it out. Before you can continue creating your new database management system, you’ll first need to weed out all of the duplicate information found in your database.
Once you’ve removed repetitive content from your database’s column, go ahead and remove it from your rows. Using the Twitter example, to separate your followers from your Twitter usernames, you could create a table labelled “Following” and a table labelled “Users”. This would ultimately allow you to better sort through your information without running into duplicate content.
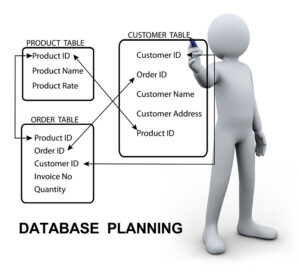
Organizing Fields into Individual Tables
Once you’ve eliminated all redundant information, go ahead and start to organize all of your fields by inserting them into tables. Remember to do this based around what the fields are describing. For instance, you could create a separate table for products, a separate table for orders, and a separate table for customer information. Microsoft Access is an example of a relational database management system. Learn how to quickly design, build and use an Access database here.
Adding Tables for Abbreviations or Codes
Create two separate tables: one for codes and one for abbreviations. Also go ahead and make one for all other codes or abbreviations that you plan on using in your relational database management system. This step is important because later on, you’ll be using these tables to generate a dropdown list of values- and these values can be chosen when you are entering information records.
Choosing a Primary Key for Your Tables
The next step is to choose a primary key for each of your tables. This “key” will ultimately allow you to identify your records that are within the tables. When doing this step, you can tell your software to automatically assign the ID number to your individual records by using a feature called the “AutoNumber Field”.
Linking Tables
With this step, you’ll want to go ahead and link all tables which contain files that are similar to one another. Remember that in an entry database that’s ordered, the “Orders” table will need to contain a field that will help identify what customer placed the order.
Also note, this field will need to match the “Primary Key Field”, that is found within the “Customer Table” (in regards to the Customers, Orders, and Product example). Basically, you’ll discover that a single table can connect with many more, or in some cases, not any. Depends on what SQL constraints you end up using. SQL Database for beginners can teach you your constraint options.
Data Integrity
There are two “rules” associated with data integrity: Primary keys cannot have a value of “NULL” and Foreign Keys can have a value of “NULL”. Data Integrity can fall under any of these categories:
-
Entity Integrity: This requires that all rows in a table have a unique identifier, or Primary Key value.
-
Domain Integrity: This applies a legal entry for any given column within your database system. It does this by restricting the range of values, the format, and the type of entries being inserted.
-
Referential Integrity: These are rows that cannot be deleted if a foreign key is pointing to the row. This is because they are being used by other records within your database system. i.e. a customer cannot be deleted from a table if they have made more than one purchase.
-
User-Defined Integrity: This applies some sort of specific rule to your data. It can fall within or outside of the other integrities (referential, entity, or domain).
Be sure to follow the rules associated with data integrity as this will help you not only better maintain your database system, but make finding information much, much easier.